|
Zun Wang
I'm a second-year CS Ph.D. student at UNC Chapel Hill, advised by Prof. Mohit Bansal. I was a Master of Machine Learning and Computer Vision student at the Australian National University advised by Prof. Stephen Gould.
Before that, I got my bachelor degree in applied mathematics from the University of Science and Technology of China.
Email /
CV /
twitter /
Google Scholar /
Github
|

|
|
Research
My research goal is to build multimodal, generative, and embodied agents, with current interests in:
- Multimodal Understanding and Generation
- Scalable Learning for Embodied Agents
- Multimodal Data Generation and Curation
|
|
Selected Papers
* denotes equal contribution, † denotes project lead
|
|
|
AnchorWeave: World-Consistent Video Generation with Retrieved Local Spatial Memories
Zun Wang, Han Lin, Jaehong Yoon, Jaemin Cho, Yue Zhang, Mohit Bansal
preprint
paper /
code /
project page
|
|
|
EPiC: Efficient Video Camera Control Learning with Precise Anchor-Video Guidance
Zun Wang, Jaemin Cho, Jialu Li, Han Lin, Jaehong Yoon, Yue Zhang, Mohit Bansal
ICML 2026
paper /
code /
project page
|
|
|
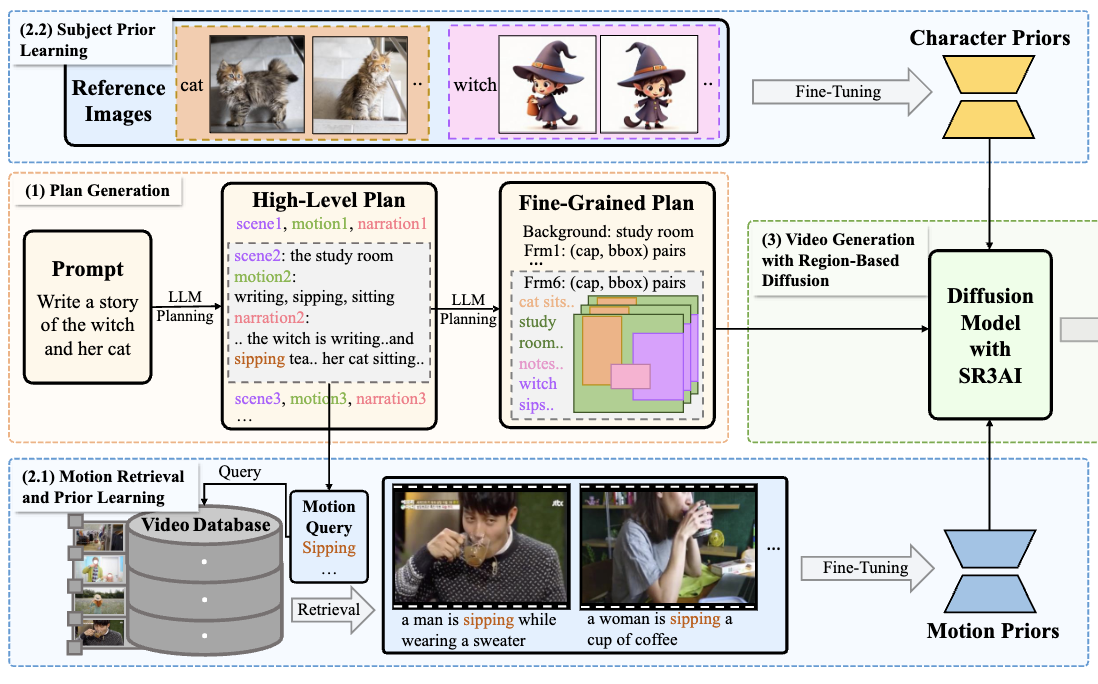
DreamRunner: Fine-grained Storytelling Video Generation with Retrieval-augmented Motion Adaptation
Zun Wang, Jialu Li, Han Lin, Jaehong Yoon, Mohit Bansal
AAAI, 2026
paper /
code /
project page
|
|
|
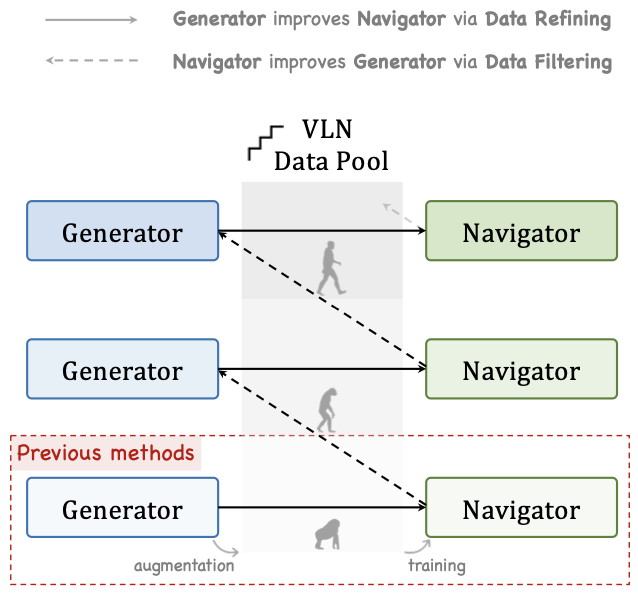
Bootstrapping Language-Guided Navigation Learning with Self-Refining Data Flywheel
Zun Wang, Jialu Li, Yicong Hong, Songze Li, Kunchang Li, Shoubin Yu, Yi Wang, Yu Qiao, Yali Wang, Mohit Bansal, Limin Wang
ICLR, 2025
paper /
code
|
|
|
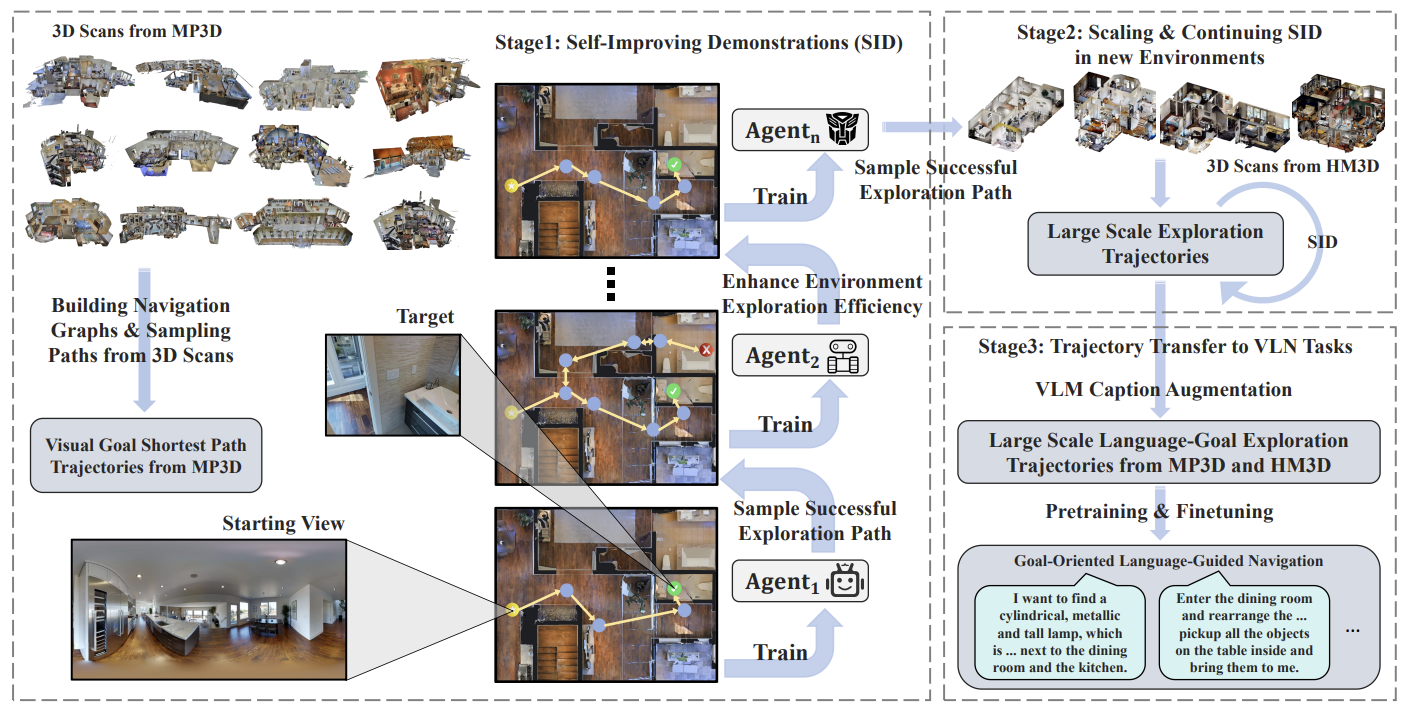
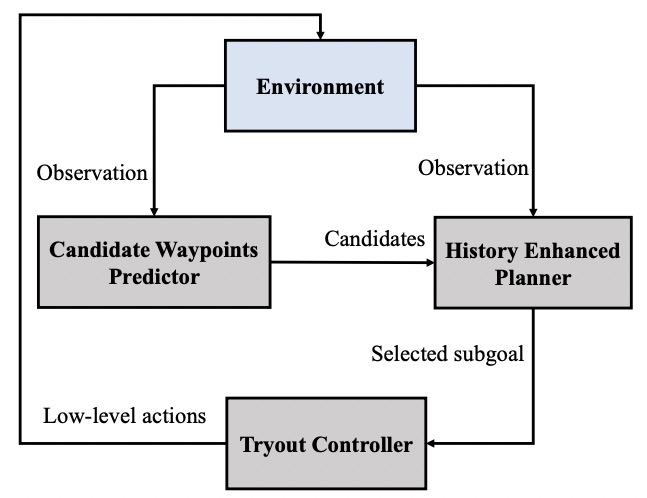
Learning Goal-Oriented Language-Guided Navigation with Self-Improving Demonstrations at Scale
Songze Li*, Zun Wang*†, Gengze Zhou, Jialu Li, Xiangyu Zeng, Limin Wang, Yu Qiao, Qi Wu, Mohit Bansal, Yi Wang
preprint
paper /
code
|
|
|
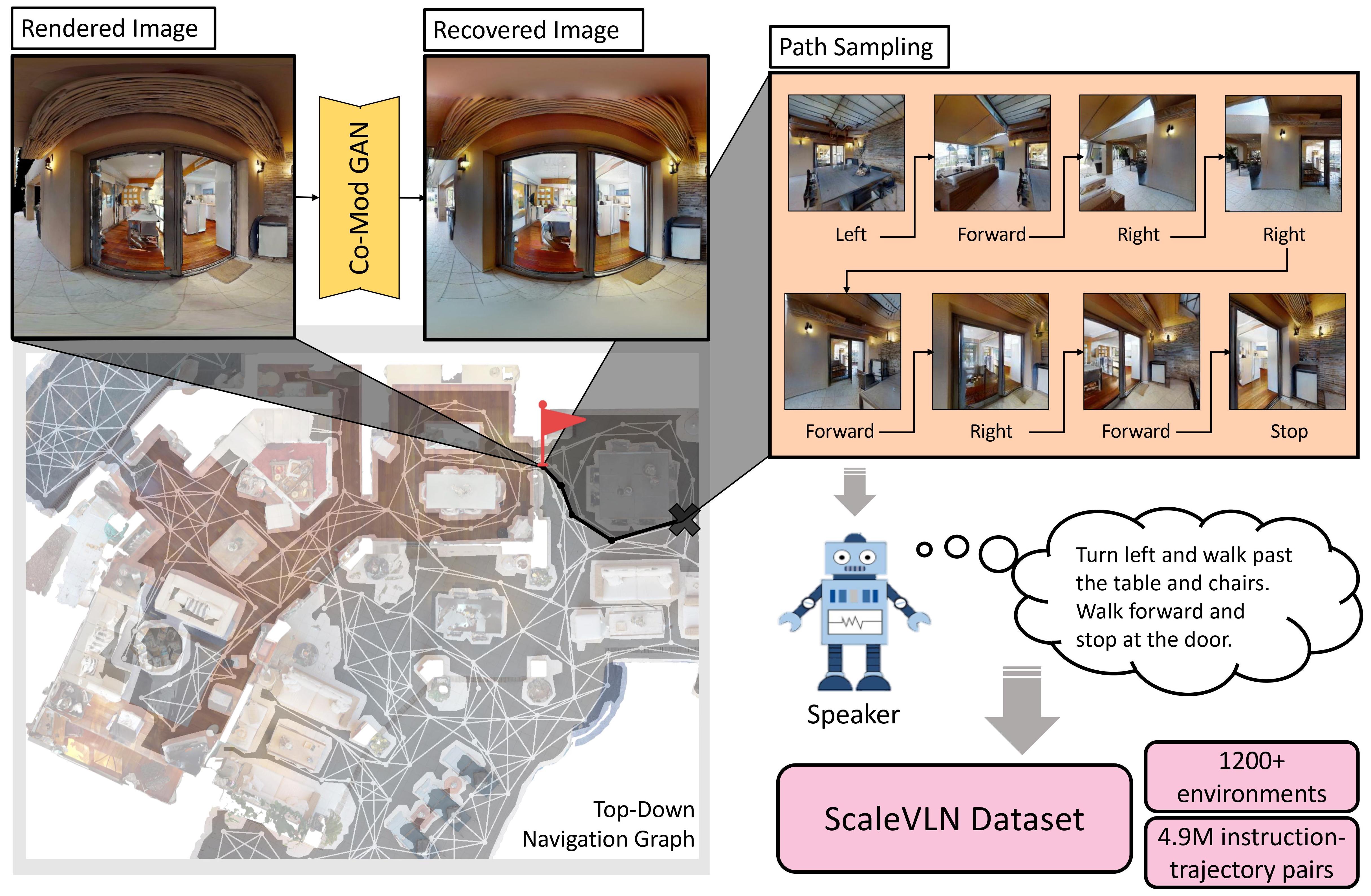
Scaling Data Generation in Vision-and-Language Navigation
Zun Wang*, Jialu Li*, Yicong Hong*†, Yi Wang, Qi Wu, Mohit Bansal, Stephen Gould, Hao Tan, Yu Qiao
ICCV, 2023, Oral presentation (1.9%)
paper /
code /
project page
|
[full list]
|
|
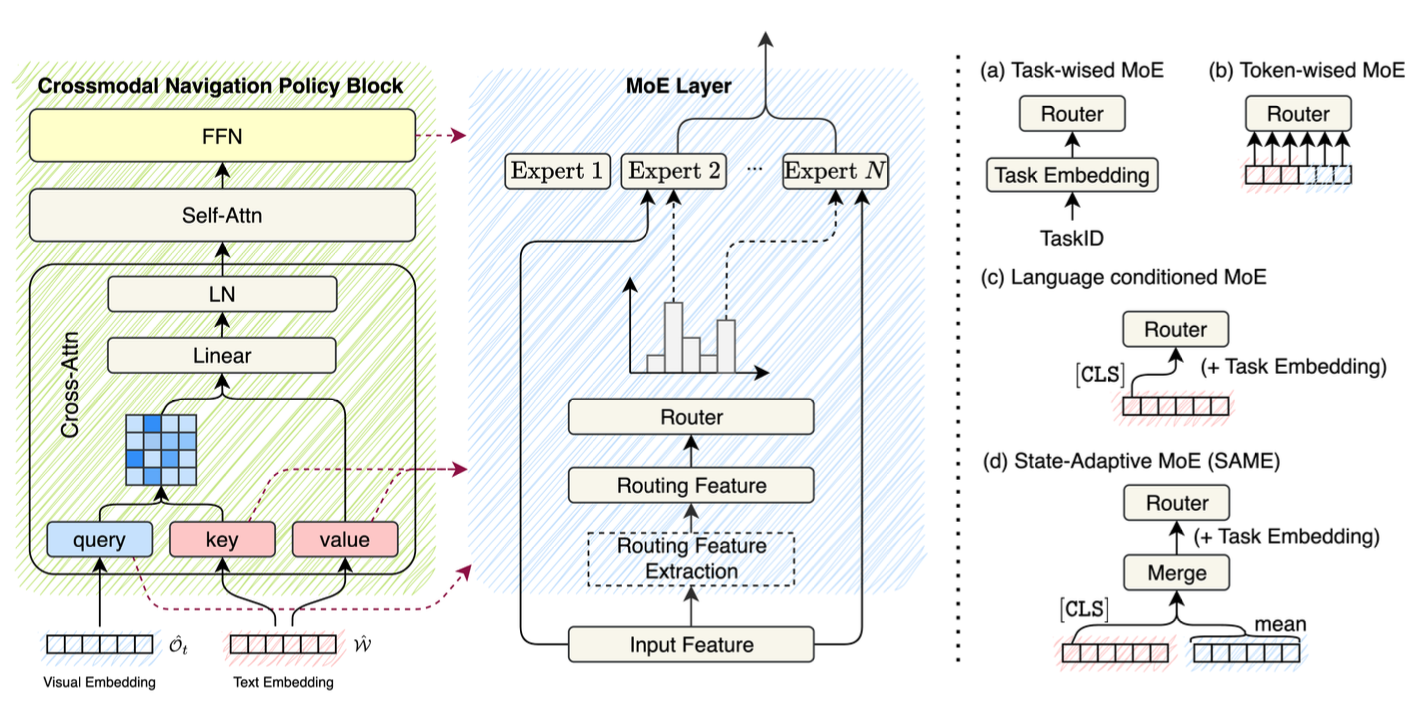
SAME: Learning Generic Language-Guided Visual Navigation with State-Adaptive Mixture of Experts
Gengze Zhou, Yicong Hong, Zun Wang, Chongyang Zhao, Mohit Bansal, Qi Wu
ICCV, 2025
paper / code
|
|
|
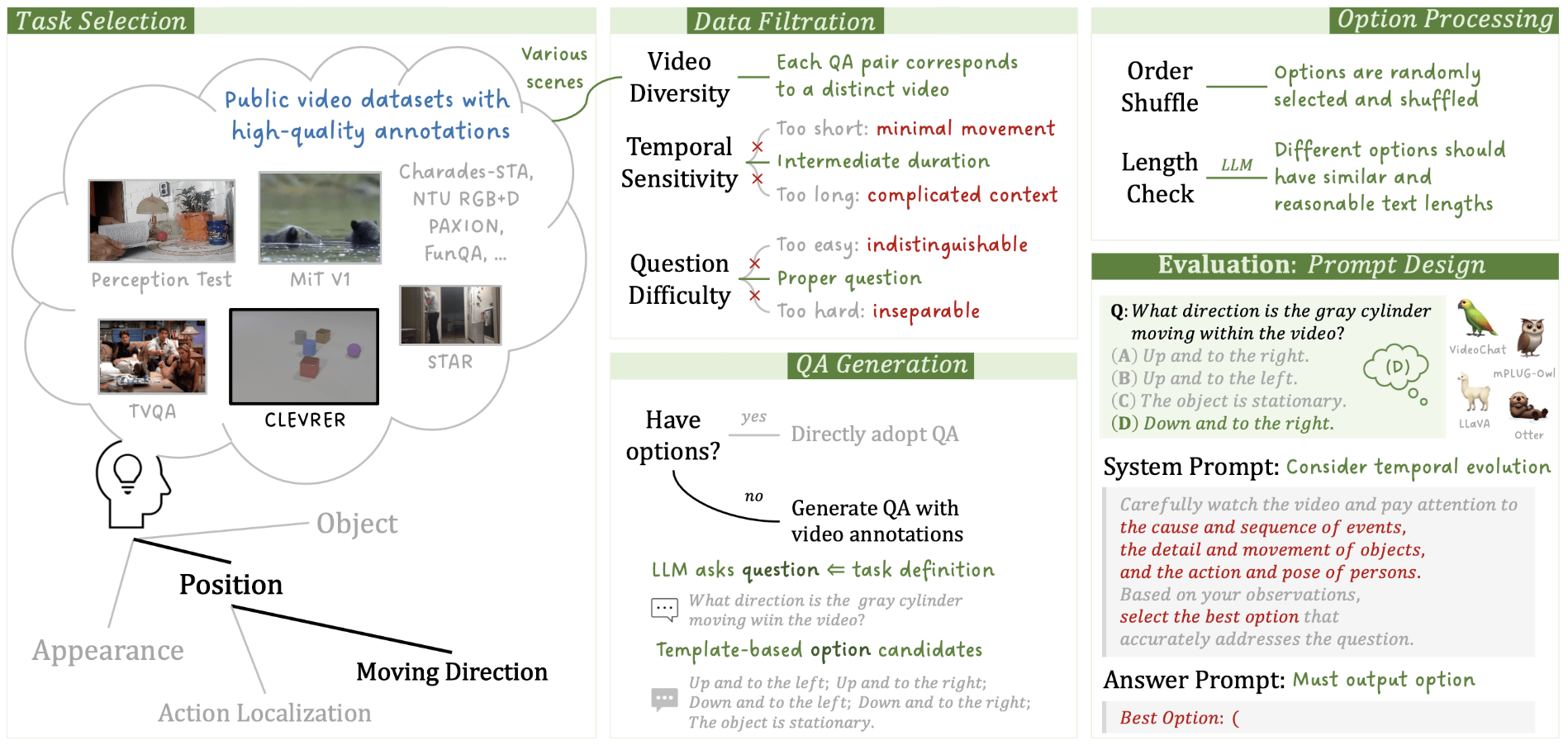
MVBench: A Comprehensive Multi-Modal Video Understanding Benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, Yu Qiao
CVPR, 2024, Highlight (3%)
paper / code
|
|
|
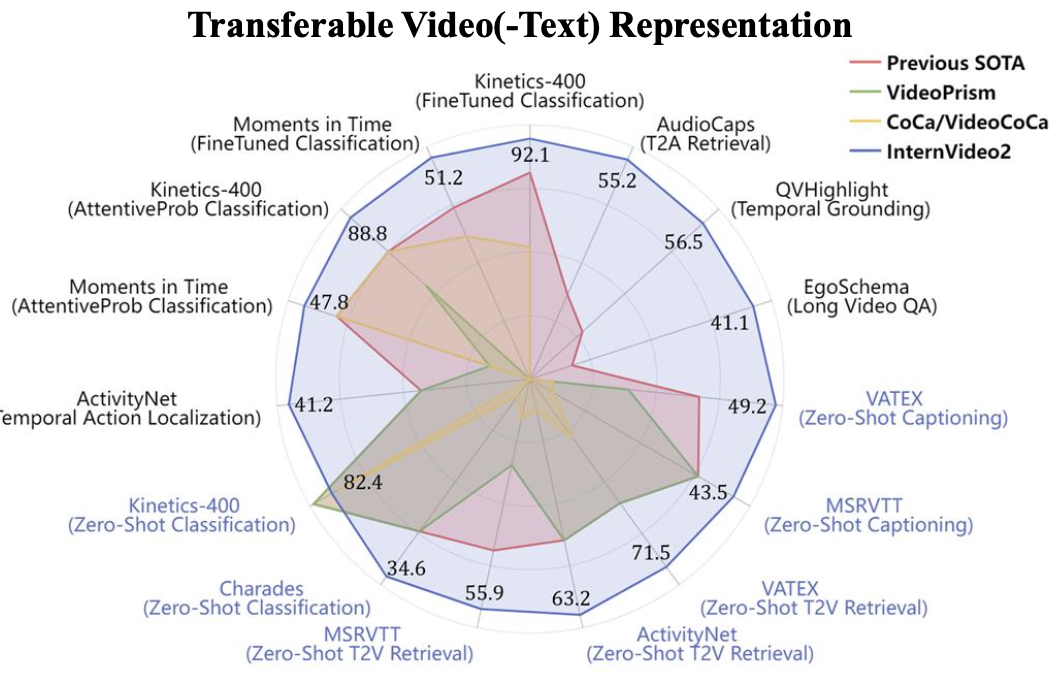
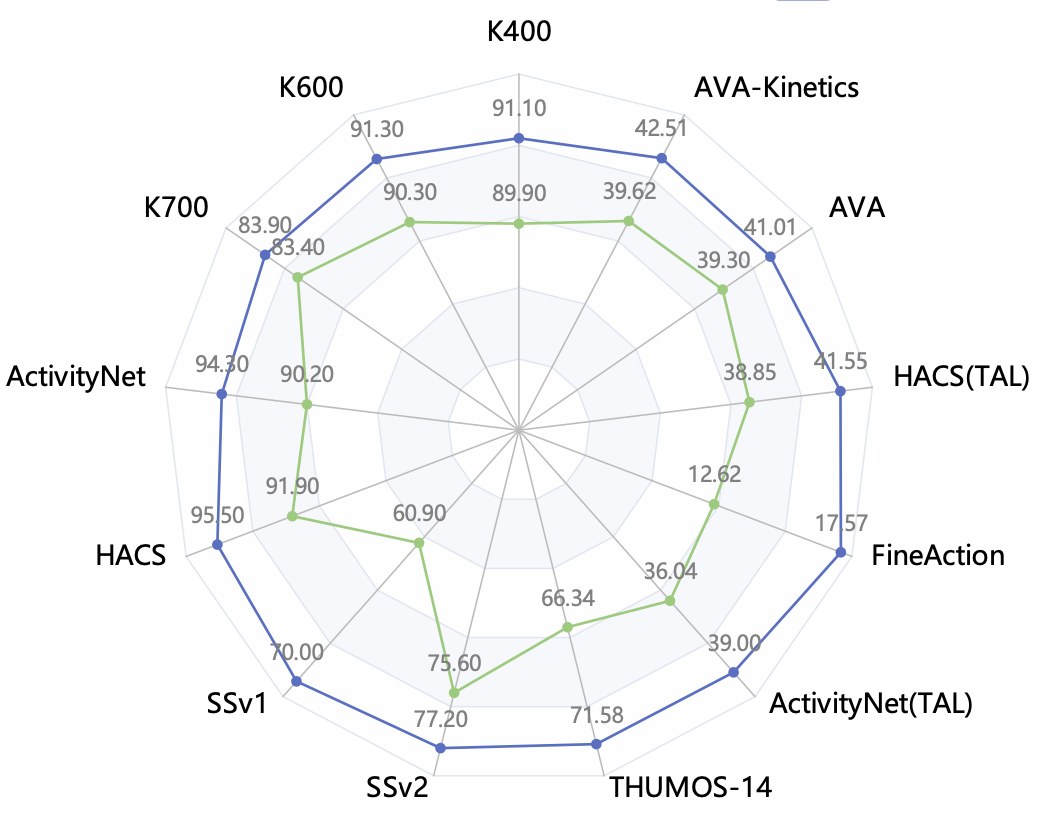
InternVideo2: Scaling Video Foundation Models for Multimodal Video Understanding
Yi Wang*, Kunchang Li*, Xinhao Li*, Jiashuo Yu*, Yinan He*, Guo Chen, Baoqi Pei, Rongkun Zheng, Jilan Xu, Zun Wang, Yansong Shi, Tianxiang Jiang, Songze Li, Hongjie Zhang, Yifei Huang, Yu Qiao, Yali Wang, Limin Wang
ECCV, 2024
paper / code
|
|
|
NavGPT-2: Unleashing Navigational Reasoning Capability for Large Vision-Language Models
Gengze Zhou, Yicong Hong, Zun Wang, Xin Eric Wang, Qi Wu
ECCV, 2024
paper / code
|
|
|
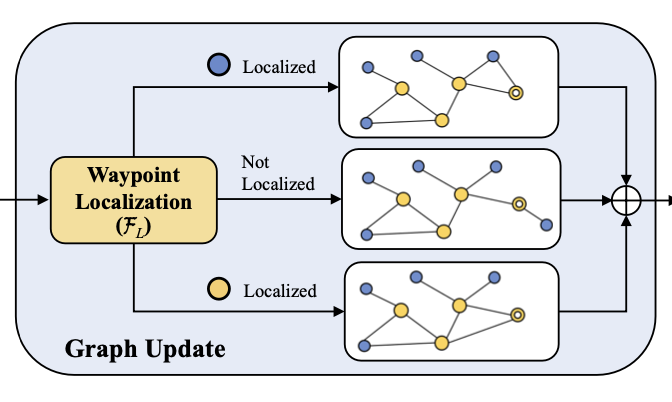
ETPNav: Evolving Topological Planning for Vision-Language Navigation in Continuous Environments
Dong An, Hanqing Wang, Wenguan Wang, Zun Wang, Yan Huang, Keji He, Liang Wang
TPAMI, 2024
paper / code
|
|
|
InternVideo: General Video Foundation Models via Generative and Discriminative Learning
Yi Wang*, Kunchang Li*, Yizhuo Li*, Yinan He*, Bingkun Huang*, Zhiyu Zhao*, Hongjie Zhang*, Jilan Xu, Yi Liu, Zun Wang, Sen Xing, Guo Chen, Junting Pan, Yali Wang, Limin Wang, Yu Qiao
Technical Report , 2022
paper / code
|
|
|
1st Place Solutions for RxR-Habitat Vision-and-Language Navigation Competition (CVPR 2022)
Dong An*, Zun Wang*, Yangguang Li, Yi Wang, Yicong Hong, Yan Huang, Liang Wang, Jing Shao
Technical Report , 2022
paper
|
|


{kind=link}