Figure 1: Overall pipeline for DreamRunner. (1) plan generation stage: we employ an LLM to craft a hierarchical video plan (i.e.,
“High-Level Plan” and “Fine-Grained Plan”) from a user-provided generic story narration. (2.1) motion retrieval and prior learning
stage: we retrieve videos relevant to the desired motions from a video database for learning the motion prior through test-time finetuning. (2.2) subject prior learning stage: we use reference images for learning the subject prior through test-time fine-tuning. (3) video generation with region-based diffusion stage: we equipt diffusion model with a novel spatial-temporal region-based 3D attention and prior injection module (i.e., SR3AI) for video generation with fine-grained control.
The Witch's Adventure with Her Cat
The Warrior's Day of Training with His Dog
The Mermaid’s Ocean Journey
The Astronaut's Day in the Space
Teddy's Cozy Day
Abstract
Storytelling video generation (SVG) aims to produce coherent and visually rich multi-scene videos that follow a structured narrative. Existing methods primarily employ LLM for high-level planning to decompose a story into scene-level descriptions, which are then independently generated and stitched together. However, these approaches struggle with generating high-quality videos aligned with the complex single-scene description, as visualizing such complex description involves coherent composition of multiple characters and events, complex motion synthesis and muti-character customization.
To address these challenges, we propose DreamRunner, a novel story-to-video generation method: First, we structure the input script using a large language model (LLM) to facilitate both coarse-grained scene planning as well as fine-grained object-level layout and motion planning. Next, DreamRunner presents retrieval-augmented test-time adaptation to capture target motion priors for objects in each scene, supporting diverse motion customization based on retrieved videos, thus facilitating the generation of new videos with complex, scripted motions. Lastly, we propose a novel spatial-temporal region-based 3D attention and prior injection module SR3AI for fine-grained object-motion binding and frame-by-frame semantic control. We compare DreamRunner with various SVG baselines, demonstrating state-of-the-art performance in character consistency, text alignment, and smooth transitions. Additionally, DreamRunner exhibits strong fine-grained condition-following ability in compositional text-to-video generation, significantly outperforming baselines on T2V-ComBench. Finally, we validate DreamRunner's robust ability to generate multi-object interactions with qualitative examples.
Method
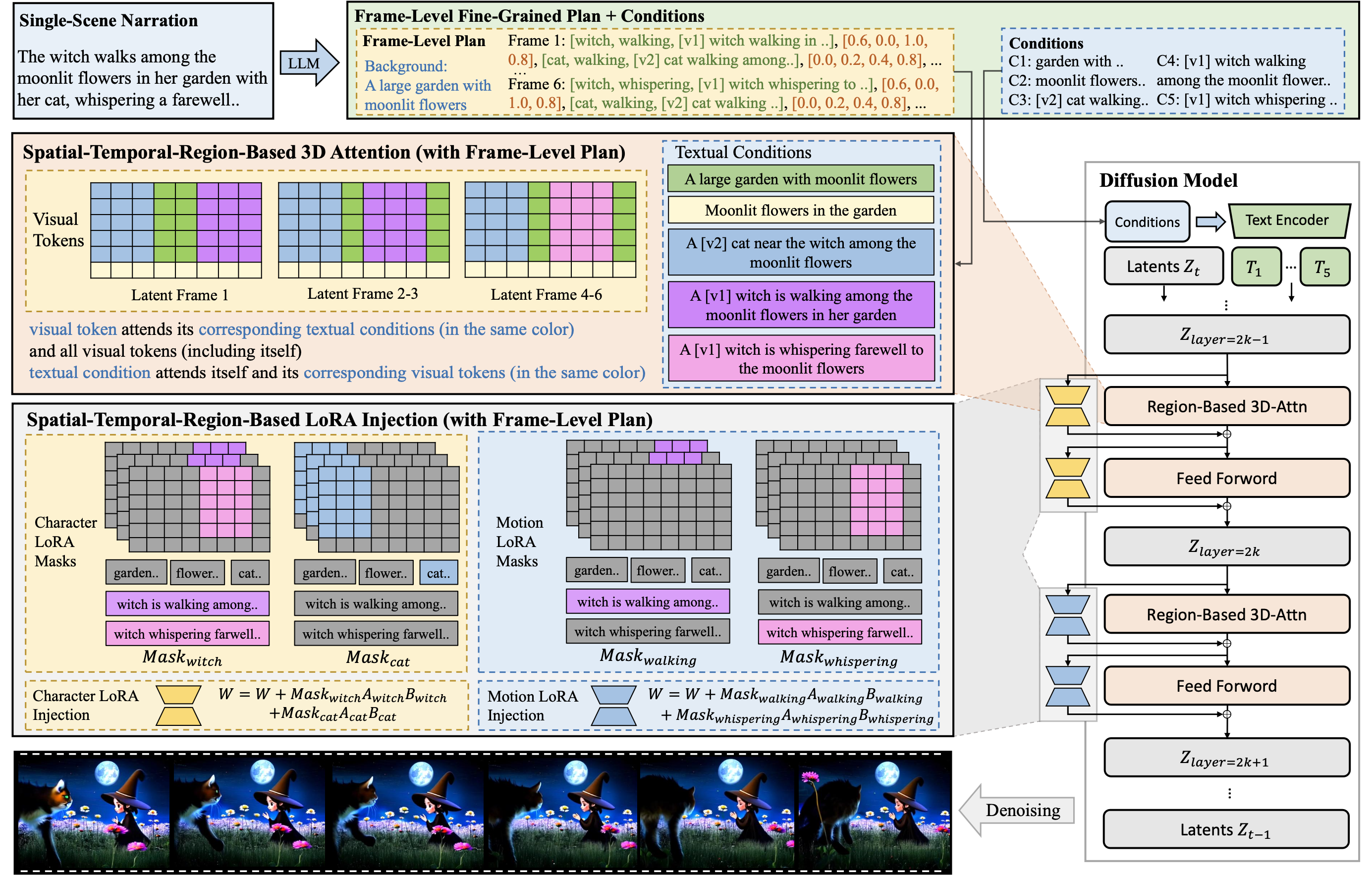
Figure 2: Implementation details for region-based diffusion with SR3AI. We extend the vanilla self-attention mechanism to spatial-temporal region-based 3D attention (upper orange part), which is capable of aligning different regions with their respective text descriptions via region-specific masks. The region-based character and motion LoRAs (lower yellow and blue parts) are then injected interleavingly to the attention and FFN layers in each transformer block (the right part). Note that though we resize the visual tokens into sequential 2D latent frames for better visualization, they are flattened and concatenated with all conditions during region-based attention.